书接上文——上文留下了一个小尾巴,即提示词的表示有两种方式,一种是注释( # 后加内容),另一种是使用文档字符串。本文将全程以文档字符串与 Copilot 交流,最后完成简单的数据分析实例展示。
文档字符串 #
文档字符串(docstring)的表示方法是在书写内容的顶部和底部添加 """ 符号,与注释相似,其被用于描述函数的功能,且不会被运行,但与注释不同的地方则在于其可避免 Copilot 持续生成注释内容。
"""
An example showing how to use docstring.
"""
正文开始以前,先回顾一下与 Copilot 沟通的流程:
- 通过注释或者文档字符串向 Copilot 提供提示词
- Copilot 生成代码
- 阅读与测试代码是否正确
- 正确则继续进行下一个任务
- 不正确则删除生成的代码并修改提示词
读取、描述与绘图 #
在 Kaggle 中搜索并下载数据集「nfl-offensive-stats-2019-2022」(美国橄榄球联盟赛事统计数据),将解压后的数据文件「nfl_offensive_stats.csv」 放入工作目录(即包含运行代码文件的文件夹)。1
Python 中的 Rainbow CSV 组件可以将 CSV 文件中的文本高亮,以便区分排布紧密的变量名称和数值。在「Extensions」中下载好 Rainbow CSV 后,在 VS Code 中打开「nfl_offensive_stats.csv」,即可看到每一行中的文本彼此之间的颜色各异。
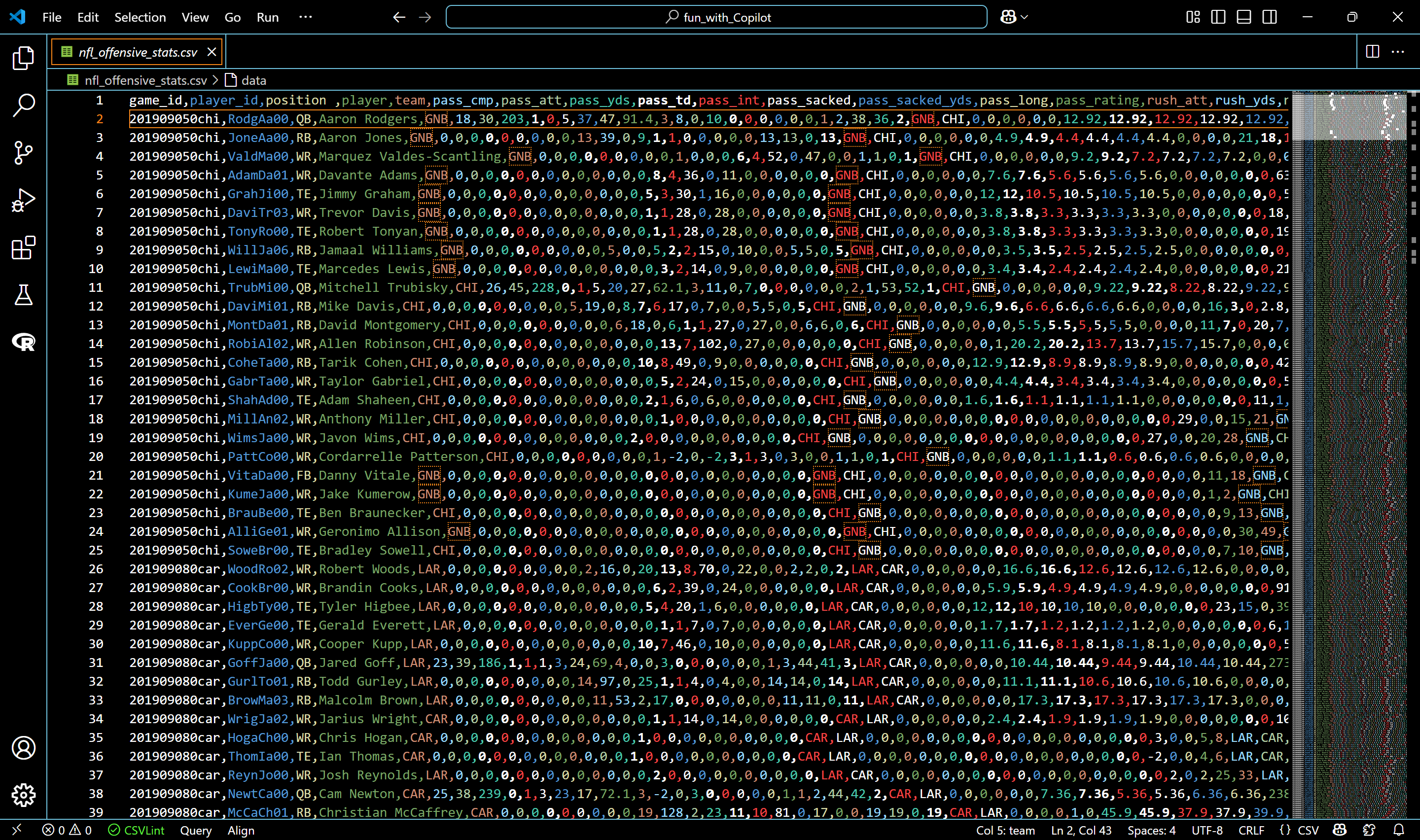
以下是 CSV 文件中的第一行,可以看到数据的所有变量。
game_id,player_id,position,player,team,pass_cmp,pass_att,pass_yds,pass_td,pass_int,pass_sacked,pass_sacked_yds,pass_long,pass_rating,rush_att,rush_yds,rush_td,rush_long,targets,rec,rec_yds,rec_td,rec_long,fumbles_lost,rush_scrambles,designed_rush_att,comb_pass_rush_play,comb_pass_play,comb_rush_play,Team_abbrev,Opponent_abbrev,two_point_conv,total_ret_td,offensive_fumble_recovery_td,pass_yds_bonus,rush_yds_bonus,rec_yds_bonus,Total_DKP,Off_DKP,Total_FDP,Off_FDP,Total_SDP,Off_SDP,pass_target_yds,pass_poor_throws,pass_blitzed,pass_hurried,rush_yds_before_contact,rush_yac,rush_broken_tackles,rec_air_yds,rec_yac,rec_drops,offense,off_pct,vis_team,home_team,vis_score,home_score,OT,Roof,Surface,Temperature,Humidity,Wind_Speed,Vegas_Line,Vegas_Favorite,Over_Under,game_date
game_id 记录的是球员名称,pass_by 记录的是传球码数。
现在的任务是:记录球员 Aaron Rodgers 在 2019-2022 年里的总传球码数。
具体来说,即找到数据表中球员姓名 game_id 标记为 Aaron Rodgers 的所有行,并将对应的传球码数 pass_by 累加起来。
第一步是先读入数据。
"""
open the csv file called "nfl_offensive_stats.csv" and read in the csv data from the file
"""
由于 Copilot 响应的不确定性,我得到的结果与书籍作者的并不一致。遗憾的是,以我目前的水平,我无法判断 Copilot 生成的代码是否准确。
# 我的结果
import pandas as pd
import csv
# 书籍作者的结果
import csv
with open('nfl_offensive_stats.csv', 'r') as f:
reader = csv.reader(f)
nfl_data = list(reader)
读入数据后,第二步便可以开始着手计算 Aaron Rodgers 的传球码数总和。
针对 Copilot 并不了解橄榄球,更不了解 Aaron Rodgers 的具体信息,因此我们需要提供明确的提示词——告诉 Copilot 哪一列是球员名称、哪一列是传球码数,并强调只在球员名为 Aaron Rodgers 的情况下对码数进行累加。
"""
In the data we just read in, the fourth column is the player and the 8th column is the passing yards. Get the sum of yards from column 8 where the 4th column value is "Aaron Rodgers"
"""
我得到的响应还是和原作者的不一致。
# 我的结果
def get_passing_yards(player_name, file_path):
"""
Get the passing yards for a specific player from the CSV file.
Parameters:
player_name (str): The name of the player.
file_path (str): The path to the CSV file.
Returns:
int: The total passing yards for the player.
"""
total_yards = 0
with open(file_path, 'r') as file:
reader = csv.reader(file)
for row in reader:
if row[3] == player_name:
total_yards += int(row[7])
return total_yards
# 作者的结果
passing_yards = 0
for row in nfl_data:
if row[3] == 'Aaron Rodgers':
passing_yards += int(row[7])
print(passing_yards)
显然,如果按照我自己得到的代码运行,不会得到任何结果2,但作者的代码可以运行出 13852 的结果。有些头疼,不过作者承诺会在后续章节让读者拥有修正 Copilot 错误代码所需的所有技能,但在此前,不要被卡在这里,继续阅读。
接下来任务是:看一看如何比较作为四分卫的 Aaron Rodgers 与其他四分卫的表现。
这意味着要先找到四分卫(QB),然后是球员,接着则是传球码数,将这些信息告知 Copilot,才算是具体的提示词。
"""
the 3rd column in data is player position, the fourth column is the player, and the 8th column is the passing yards. For each player whose position in column 3 is "QB", determine the sum of yards from column 8.
"""
我收到的反馈仍然与作者不同。感觉,作者的 Copilot 更智能……还提供了注释说明。
# 我的结果
passing_yards = 0
for row in data[1:]:
if row[2] == 'QB':
passing_yards += int(row[7])
# 作者的结果
# creat a dictionary to hold the player name and passing yards
passing_yards = {}
# loop through the data
for row in nfl_data:
# check if the player is a quarterback
if row[2] == 'QB':
# check if the player is already in the dictionary
if row[3] in passing_yards:
# add the passing yards to the existing value
passing_yards[row[3]] += int(row[7])
else:
# add the player to the dictionary
passing_yards[row[3]] = int(row[7])
最后打印结果。
"""
print the sum of the passing yards sorted by sum of passing yards in descending order
"""
虽然做好了得不到正确结果的心理准备,但为什么 Copilot 给我提供的建议包括文档字符串的一半呢?
# 我的结果
passing_yards = sorted(passing_yards, reverse=True)
print(passing_yards)
"""
# 作者的结果
for player in sorted(passing_yards, key=passings_yard.get, reverse=True):
print(player, passing_yards[player])
不过,如果考虑到 Copilot 的反馈可能跟使用者的 GitHub 账号有关,这或许不是十分反常的状况。书籍的两位作者都是资深的程序员和计算机教授,他们的 GitHub 数据库想必十分丰富。如同他们对 Copilot 的评价:
我们必须指出,身为拥有多年编程经验的教育者,这段代码确实令人赞叹。在我们执教的大学课程里,我们可能会在期末考试上布置类似的题目,但估计只有不到半数的学生能够正确完成。 Copilot 选择了使用字典(这里说的字典不是类似英语字典那种的普通字典,而是一种在 Python 中用于存储数据的方式)来存储数据,这是个明确的选择,而且它还巧妙地采用了排序方法来提升数据的展示成果。
如果想要排除某位运动员(如 Aaron Rodgers)进行比较,可以直接说明。
"""
print the sum of the passing yards sorted by sum of passing yards in descending order
Do not include Aaron Rodgers because he wins too much
"""
for player in sorted(passing_yards, key=passing_yards.get, reverse=True):
if player != "Aaron Rodgers":
print(player, passing_yards[player])
最后的最后,上一些强度,要求 Copilot 绘图。具体要求是绘制一张仅展示传球码数达到 4000 以上的四分卫的情况图。
"""
plot the players by their number of passing yards only for players with more than 4000 passing yards
"""
我得到的反馈显然不足。
# 我的结果
import matplotlib.pyplot as plt
import pandas as pd
打开面板,上面的每一条建议内容倒是很多,但不清楚是否准确。
# 作者的结果
import matplotlib.pyplot as plt
import numpy as np
# create a list of players
players = []
# create a list of passing yards
yards = []
# for each player in the dictionary
for player in passing_yards:
# if the player has more than 4000 passing yards
if passing_yards[player] > 4000:
# add the player to the list of players
players.append(player)
# add the passing yards to the list of passing yards
yards.append(passing_yards [player])
# create a numpy array of the passing yards
yards = np.array(yards)
# create a numpy array of the players
players = np.array(players)
# sort the players by the passing yards
print(np.argsort(yards))
players = players[np.argsort(yards)]
# sort the passing yards
yards = np.sort(yards)
# create a figure
plt.figure()
# create a bar chart of the players and their passing yards
plt.bar(players, yards)
#rotate the x axis labels
plt.xticks(rotation=90)
# show the plot
plt.show()
按照作者的说法,他们多次向 Copilot 提供过代码,这只是其中一个具有代表性的回答,比较复杂,最后生成了下面的柱状图。
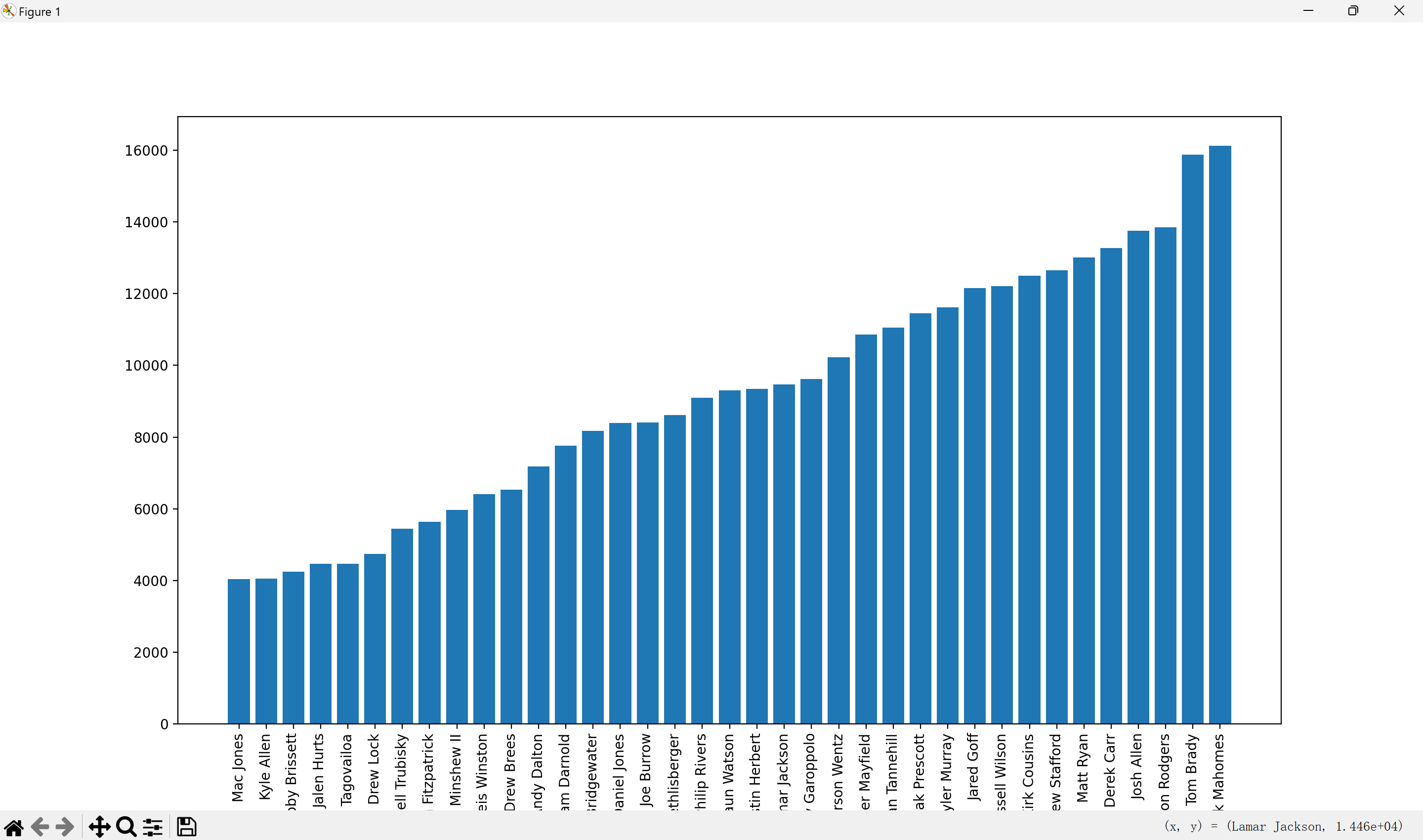
可以看到,柱状图展示了这样一些信息:y 轴是传球码数,x 轴是球员名字,球员按照传球码数从少(最少4000)到多进行排序。虽然 y 轴缺少标签,x 轴的名字被底部截断,但我们提供的提示词本身也是十分简短的,Copilot 却能正确导入用于绘图的 matplotlib,利用 numpy 进行数据操作,还考虑到球员名字旋转以作为 x 轴标签打印出来,最后生成一张完整的图片——或许可以说得上十分了不起了?
最后吐个槽,在画图的指令里导入了一个用于绘图的 Python 模块 matplotlib,需要先安装该模块,使用命令:
pip install matplotlib
过去我在 GitHub 冲浪时,偶尔在一些有意思的仓库中都能看到 pip install 开头的命令,但愣是找不到说明是在 Python 中进行运行。直到这一次在这本书里,我才知道这是用来下载 Python 模块的。而关于 Python 模块,书籍也做了介绍:
Python 模块
模块扩展了 Python 这门编程语言的功能范畴。 Python 拥有大量模块,它们能帮助你完成各种各样的任务,包括数据分析、网站创建和电子游戏开发等。看到代码中的 import 语句,你就知道代码需要使用 Python 模块了。 Python 并不会自动安装所有模块,因为其中的大部分你可能根本用不到。因此,当你希望使用某个模块时,需要自行安装包含该模块的“包”(package)。
小结 #
总的来看,我们完全可以通过人类的自然语言提供提示词,获得 Copilot 提供的计算机代码,进而完成“输入数据→加工数据→输出结果→结果可视化”这样一个流程。
当然,这里面仍然存在一些挑战。应该向 Copilot 提供怎样的提示词,才能确保它理解我们的意思并提供合适的代码?而在完成提问和得到结果后,我们得到的代码是否正确?如果不对怎么办?如同我从 Copilot 得到的结果就与书籍中两位作者得到的完全不一样,那么这时候便存在两种情况:我得到的代码也是正确的,只是和作者的不一样;我得到的代码是错误的。这便要求使用者对相关代码要有最基本的了解。
由此可以总结掌握 Copilot 需要的几项能力:
- 正确描述问题的能力。这需要能够具体细致地描述问题,总不能直接和 Copilot 说「给我 Aaron Rodgers 的传球码数」——Copilot 可能根本不知道数据存储在哪里,数据格式是什么,球员和传球码数是哪两行,也不知道 Aaron Rodgers 是球员。这便要求使用者可以做到将一个问题分解成多个小任务,同时越具体越好,而这有助于增加 Copilot 生成正确代码的可能性。
- 理解代码。要写出好的提示词,必须了解基本的代码逻辑,才能提好问题。当然,理解代码还意味着确保 Copilot 生成的代码是否合理。好比写作论文时向 AI 寻找文献,如果不加辨别,可能便使用了其提供的虚假文献。而没有辨别代码正确性、适用性的能力,那么分析流程便无法进行下去,甚至更加严重——代码全部运行完成了,但却得到误导性的结果。